🌊 Spring Cache + Redis Cache
![]()
![]()
![]()
[!IMPORTANT]
모든 마크다운 파일은 직접 본인이 작성하였습니다.
📌 개요
Spring Boot Starter Cache와 Redis를 활용한 캐시 전략 구현 및 성능 테스트 결과를 공유하고,
나에 생각을 공유
🏗 아키텍처
오늘은 Spring Boot Starter Cache + Redis 를 이용한 캐시 전략을 알아보았다.

동작 프로세스
- Client가 API 서버에 데이터 요청
- Redis Server에서 캐시 확인
- Cache Hit 시 DB 접근 없이 즉시 응답
💡 캐시란?
자주 사용하는 데이터나 값을 미리 복사해 놓는 임시 저장소
캐시를 사용함으로써 얻을 수 있는 효율
자주 접근하는 데이터를 메모리에 임시 저장함으로써 데이터베이스 쿼리 부하를 줄이고 응답 시간을 크게 단축시키며, 웹 서버와 데이터베이스 서버의 자원 사용률을 최적화하여 트래픽 급증 시에도 안정적인 서비스를 제공할 수 있게 합니다.
이런 캐시전략을 수립하는것을 확인하기 위해 실습을 진행해보았다.
🛠 개발 환경
- Language: Java 17
- Framework: Spring Boot 3.0.6
- Dependencies:
- Spring Web
- Spring Data JPA
- Spring Data Redis
- Spring Cache
- Cache Server: Redis
- 부하테스트: Vegeta (Open Source)
실습 조건
- 2개의 API 구현
- Cache 전략 없는 DB Connection Fetch API
- Cache 전략을 사용하는 Fetch API
- API별 Vegeta 부하테스트 진행
- API별 부하테스트 결과 비교
Spring Cache 사용 전략 과정
- Spring Cache를 적절하게 커스텀하여 캐싱방식을 어노테이션 방식으로 추상화 진행
@Configuration // Spring 설정 클래스임을 나타냄
@EnableCaching // Spring의 캐시 기능을 활성화
public class CacheConfig {
// 캐시 이름을 상수로 정의하여 재사용성과 유지보수성 향상
public static final String CACHE1 = "cache1";
public static final String CACHE2 = "cache2";
// 캐시별 속성을 정의하는 내부 클래스
@AllArgsConstructor // 모든 필드를 파라미터로 받는 생성자 자동 생성
@Getter // getter 메서드 자동 생성
public static class CacheProperty {
private String name; // 캐시 이름
private Integer ttl; // 캐시 만료 시간(초)
}
@Bean
public RedisCacheManagerBuilderCustomizer redisCacheConfiguration() {
// Jackson의 다형성 타입 검증기 설정
// Object 클래스의 모든 하위 타입에 대한 직렬화/역직렬화 허용
PolymorphicTypeValidator ptv = BasicPolymorphicTypeValidator.builder()
.allowIfSubType(Object.class)
.build();
// ObjectMapper 설정
var objectMapper = new ObjectMapper()
.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false) // JSON에 알 수 없는 필드가 있어도 역직렬화 실패하지 않음
.registerModule(new JavaTimeModule()) // Java 8의 LocalDateTime 등 날짜/시간 타입 지원
.activateDefaultTyping(ptv, ObjectMapper.DefaultTyping.NON_FINAL) // JSON에 타입 정보를 포함시켜 정확한 타입으로 역직렬화 가능하게 함
.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS); // 날짜를 타임스탬프가 아닌 ISO-8601 형식으로 직렬화
// 캐시별 속성 정의
// CACHE1: 5분(300초) 유지
// CACHE2: 30초 유지
List<CacheProperty> cacheProperties = List.of(
new CacheProperty(CACHE1, 300),
new CacheProperty(CACHE2, 30));
// Redis 캐시 설정을 커스터마이징하는 빌더 반환
return (builder -> {
cacheProperties.forEach(cache -> {
builder.withCacheConfiguration(cache.getName(),
RedisCacheConfiguration.defaultCacheConfig()
.disableCachingNullValues() // null 값은 캐시하지 않음
.serializeValuesWith( // 캐시 키는 문자열로 직렬화
RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith( // 캐시 값은 JSON으로 직렬화
RedisSerializationContext.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer(objectMapper)))
.entryTtl(Duration.ofSeconds(cache.getTtl()))); // 캐시 엔트리의 만료 시간 설정
});
});
}
}- Fetch API Service Logic 구현
- 1번과정에서 설정한 Custom Cache Config 를 통해 캐시전략을 추상화 하였다.
- Service 로직을 실행 하기 전에 AOP 기반으로 파라미터 ID를 통해 Redis Server에 Cache Check를 진행하게 된다.
/**
* @Cacheable 어노테이션을 사용한 캐시 구현
*
* 1. 동작 방식:
* - 최초 호출 시: DB에서 데이터를 조회하고 Redis에 저장
* - 이후 호출 시: Redis에서 캐시된 데이터를 직접 반환 (DB 조회 없음)
*
* 2. 설정 설명:
* - cacheNames = CacheConfig.CACHE1: 캐시 저장소 이름 지정
* - key = "'user:' + #id": 캐시 키 형식을 'user:{id}' 로 지정
*
* 3. 장점:
* - 반복적인 DB 조회 감소로 성능 향상
* - 캐시 관련 보일러플레이트 코드 제거
* - AOP 기반으로 비즈니스 로직과 캐시 로직 분리
*
* @param id 사용자 ID
* @return 찾은 사용자 정보
* @throws RuntimeException 사용자를 찾을 수 없는 경우
*/
@Cacheable(cacheNames = CacheConfig.CACHE1, key = "'user:' + #id")
public User getUser3(Long id) {
return userRepository.findById(id).orElseThrow(() -> new RuntimeException("User not found"));
}부하테스트 과정
- Vegeta 설치
# homebrew를 통해 vegeta 설치
brew install vegeta- vegeta 를 통해 Fetch API를 각각 vegeta를 통해 부하테스트 진행
테스트 조건
- 15초 동안 진행
- 5000/1s 초당 5000 트래픽 발생
- 100개 Thread 사용
부하테스트 전
- 현재 아키텍쳐의 전부는 Docker Container로 실행되어 있기때문에
Docker Stats 를 사용한 리소스를 감지하여 테스트 진행
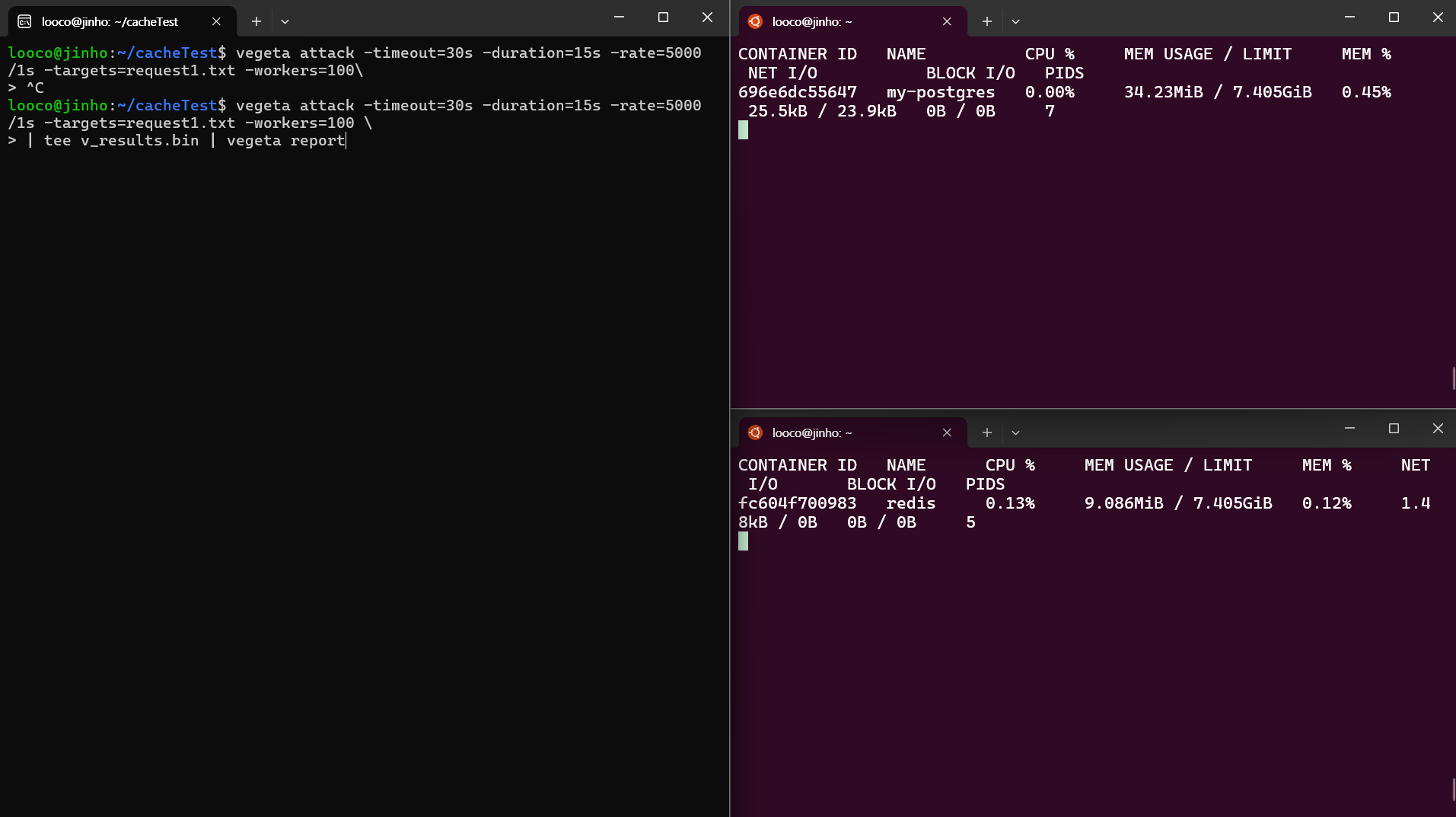
부하테스트 후
- 캐시전략을 수립하지 않은 Fetch API
- 1번사진에서 API 요청별로 DB Connection 으로 인해 Postgres Server CPU가 과부화 됨을 알 수 있다.
- 2번사진에서 Succes 가 89% 로 현저하게 떨어짐을 알 수 있다 ( 부화로 인한 I/O로 인해 모든 Request를 처리하지 못함)


- 캐시전략을 수립한 Fetch API
- 1번 사진을보아 알 수 있듯이 캐시전략을 사용해 DB는 사용하지 않고 , Redis만 리소스를 사용하는것으로 확인
- 2번 사진에서는 DB보다 높은 성공률을 보여줌
- 100%가 아닌 이유는 타임아웃 설정으로 인해
초당 10,000개의 매우 높은 동시 요청으로 인해 서버가 일부 요청을 제한된 시간(30초) 내에 처리하지 못했기 때문이다.
이런점은, 인프라 구조 또는 서버 리소스에 따라 Redis ( active,idle ) 설정을 해주는 것으로 해결 할 수 있다.


📝 후기
1. 캐시 전략의 효율적인 활용
✅ 좋은 사용 사례
- 효율적인 리소스 관리 가능
- 서비스 확장성 개선
- 시스템 성능 최적화
⚠️ 주의해야 할 점
- 무분별한 캐시 전략 남발 시 문제 발생
- 데이터 정합성 이슈
- 불필요한 메모리 낭비
- 운영 관리 복잡도 증가
핵심: 성능 개선이 필요한 곳에 선별적으로 적용하는 것이 중요
2. Spring Cache 첫 도입 소감
기존 방식 vs Spring Cache
| 구분 | RedisTemplate | Spring Cache |
|---|---|---|
| 구현방식 | API 별 Cache 정책 로직 구현 필요 | Config 설정으로 추상화 |
| AOP 구현 | 별도 구현 필요 | 내장 지원 |
| 복잡도 | 높음 | 상대적으로 낮음 |
장점
- 설정 기반의 간편한 캐시 관리
- 효율적인 코드 작성 가능
- 높은 추상화 수준
설정이 다소 복잡할 수 있으나, 추상화를 통한 효율적인 코드 작성이 가능한 점이 큰 장점
Good~
'나의 여정 > 이것저것' 카테고리의 다른 글
| Redis Replication ( Cluster ) (1) | 2024.12.08 |
|---|
